目次
刀根「経営効率化...」の例題
g.in = c(1,rep(0,7),0,0,0)
g.mat = rbind(c(4,-4,-7,-8,-4,-2,-10,-3,-1,0,0),
c(3,-3,-3,-1,-2,-4,-1,-7,0,-1,0),
c(0,1,1,1,1,1,1,1,0,0,-1))
g.rhs = c(0,0,1)
g.dir = rep("=", 3)
soln = lp ("min", g.in, g.mat, g.dir, g.rhs)
soln$solution
g.in = c(1,rep(0,7),0,0,0)
g.mat = rbind(c(7,-4,-7,-8,-4,-2,-10,-3,-1,0,0),
c(3,-3,-3,-1,-2,-4,-1,-7,0,-1,0),
c(0,1,1,1,1,1,1,1,0,0,-1))
g.rhs = c(0,0,1)
g.dir = rep("=", 3)
soln = lp ("min", g.in, g.mat, g.dir, g.rhs)
soln$solution
g.in = c(1,1)
g.mat = rbind(c(5,3),c(4,5))
g.rhs = c(15,20)
g.dir = rep("<=", 2)
soln = lp ("max", g.in, g.mat, g.dir, g.rhs)
soln$solution
g.dir2 = rep(">=", 2)
soln = lp ("min", g.rhs, t(g.mat), g.dir2, g.in)
soln$solution
CCR() は、投入行列と算出行列と DMU の番号を与えて、その DMU の効率値と、それを実現するウェイトベクトルを計算する関数である。
投入量の行列、産出量の行列は、行に DMU、列に項目名を配置する。DMU の番号は、1から投入行列の行数以下の整数とする。行列のサイズ違反、DMU の指定違反についてのチェックはしない。
計算結果は、効率値($opt)、入力項目のウェイトベクトル($win)、出力項目のウェイトベクトル($wout)をlist として返す。
線形計画法の解を求めるために、lp() 関数を使う。
lp("min"/"max", 目的関数係数ベクトル, 係数行列, "="/">="/"<=", 定数ベクトル)
lp() を使うために lpSolve パッケージを使うので、最初に、library(lpSolve) を実行させる必要がある。
lpSolve がない場合は、install.packages("lpSolve") を実行してインポートしなければいけない(ここを参照のこと)。
as.matrix() は、ベクトルを1列の行列として扱うことを許す関数である。投入、あるいは算出の項目数が1の場合は、ncol() 関数の引数がベクトルとなり、正しい結果が得られないので、この関数が必要になる。
#### 投入行列 input と算出行列 output が与えられているとき、dmu の効率性を計算する。
#### 行列は、DMU を行に、項目を列にしたものを与える。
#### 結果は、効率値($opt)と、投入ベクトルの係数($win)、算出ベクトルの係数($wout)。
CCR <- function(input, output, dmu) {
matin <- as.matrix(input)
matout <- as.matrix(output)
ndmu <- nrow(matin)
nin <- ncol(matin)
nout <- ncol(matout)
g.in <- c(rep(0,nin),matout[dmu,])
g.mat <- rbind(c(matin[dmu,],rep(0,nout)), cbind(-matin,matout))
g.dir <- c("=", rep("<=", ndmu))
g.rhs <- c(1,rep(0,ndmu))
soln <- lp("max", g.in, g.mat, g.dir, g.rhs)$solution
return(list(opt=sum(soln[nin+1:nout]*matout[dmu,]),
win=soln[1:nin], wout=soln[nin+1:nout]))
}
#### 投入行列 input と算出行列 output が与えられているとき、すべての DMU の効率性を計算し、
#### 効率値($opt)と、投入ベクトルの係数($win)、算出ベクトルの係数($wout)の一覧表を返す。
#### DMU を行に、入出力の各項目を列に配置してある。
DEAtable <- function(input, output) {
n <- nrow(as.matrix(input))
tbl <- sapply(1:n, function(k) unlist(CCR(input, output, k)))
return(t(tbl))
}
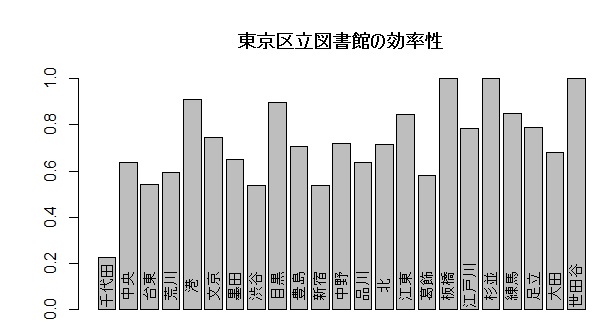
使用例 データは、刀根薫「経営効率性の測定と改善」46ページから引用した、東京の区立図書館の「蔵書数」「職員数」「登録者数」「貸出冊数」である。
> install.packages("lpSolve") # パッケージのインストール
> library(lpSolve) # ライブラリを呼び出す
> libr < read.table("clipboard", header=TRUE) # 表形式のデータをクリップボード経由で読み込む
> (input <- libr[,2:3]) # (この場合は)2入力2出力のデータを扱う
蔵書 数職員数
1 163.523 26
2 338.671 30
3 281.655 51
4 400.993 78
(以下省略)
> (output <- libr[,4:5])
登録者数 貸出冊数
1 5.561 105.321
2 18.106 314.682
3 16.498 542.349
4 30.810 847.872
(以下省略)
> CCR(input, output, 1)
$opt
[1] 0.2260062
$win
[1] 0.00000000 0.03846154
$wout
[1] 0.04064128 0.00000000
> (dealib = round(DEAtable(input,output),6))
opt win1 win2 wout1 wout2
[1,] 0.226006 0.000000 0.038462 0.040641 0.000000
[2,] 0.637738 0.000000 0.033333 0.035222 0.000000
[3,] 0.540055 0.003550 0.000000 0.000000 0.000996
[4,] 0.593021 0.002494 0.000000 0.000000 0.000699
(以下省略)
> bpx <- barplot(dealib[,1],main="東京区立図書館の効率性")
> text(bpx,0.1,labels=libr[,1],srt=90,cex=0.8)
注
round(.., 6) は、小数点7桁以下を四捨五入する関数である。barplot() の戻り値は、各棒の左端の x 座標である。text(..., srt=90, ...) はテキストを左に90度回転して表示するオプション、cex=0.8 はフォントの大きさを8割に縮小表示するオプションである。